Conditional GAN
Generating right half of an MNIST digit given the left half.
In this task, you should train a conditional GAN to generate the right half of MNIST images, given the left half.
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
from time import time
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
Load the dataset¶
Load the MNIST dataset bellow. You can use either torchvision.datasets.MNIST or sklearn.datasets.fetch_openml() or any other way to load the dataset.
X, y = fetch_openml(name='mnist_784', return_X_y=True, as_frame=False)
y = y.astype('int32')
X = X.reshape((X.shape[0], 28, 28)).astype('float32')
X.shape
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.1)
(X_train.shape, X_test.shape, X_val.shape), (y_train.shape, y_test.shape, y_val.shape)
images_train = X_train / 255
images_val = X_val / 255
images_test = X_test / 255
Design your model¶
Implement your GAN below using torch.nn modules. Feel free to add extra cells. The generator should construct right half of an image given the left half of it and a noise. The general structure of this GAN is shown below.
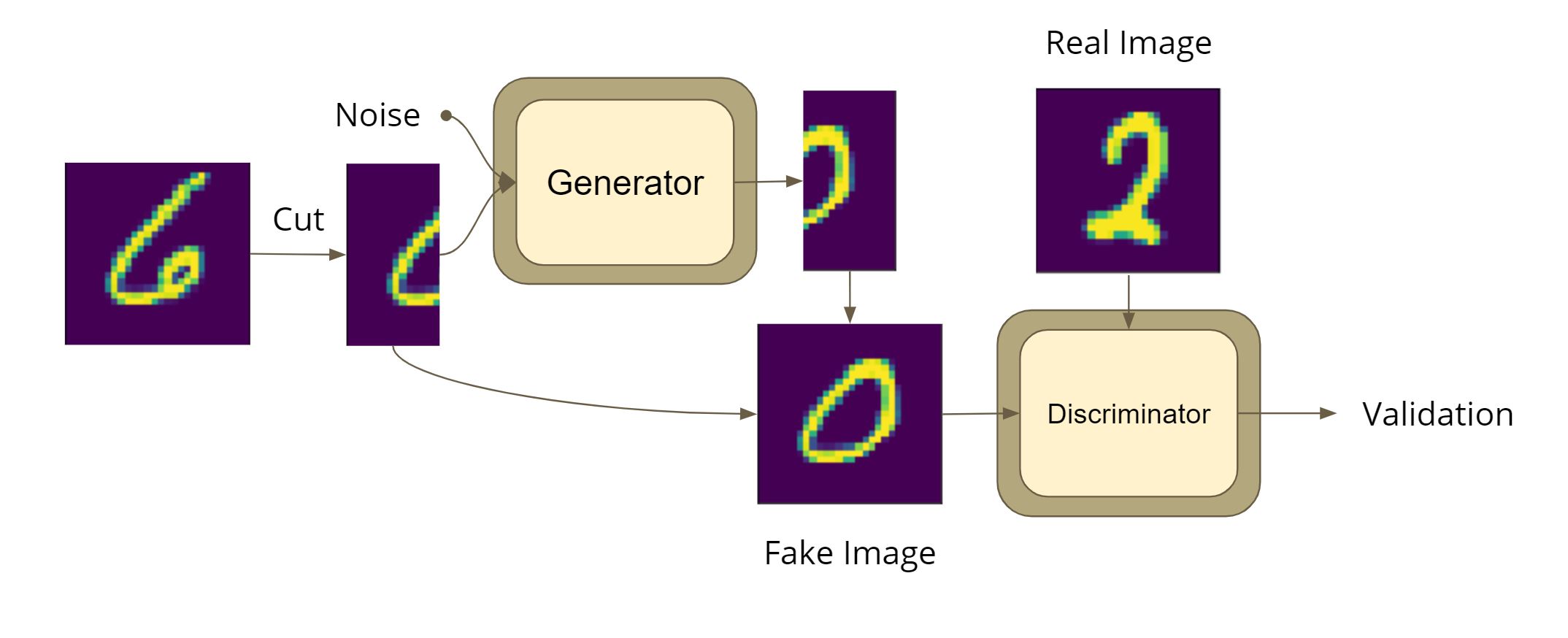
class ImageConv(nn.Sequential):
def __init__(self):
super().__init__( # B 1 28 28
nn.BatchNorm2d(num_features=1),
nn.Conv2d(1, 64, 3, stride=1, padding=3), # B 64 32 32
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64, 3, stride=1, padding=1), # B 64 32 32
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, stride=2, padding=0), # B 64 16 16
nn.Dropout2d(0.2, inplace=True),
nn.BatchNorm2d(num_features=64),
nn.Conv2d(64, 128, 3, stride=1, padding=1), # B 128 16 16
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 128, 3, stride=1, padding=1), # B 128 16 16
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, stride=2, padding=0), # B 128 8 8
nn.Dropout2d(0.2, inplace=True),
nn.BatchNorm2d(num_features=128),
nn.Conv2d(128, 256, 3, stride=1, padding=1), # B 256 8 8
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 256, 3, stride=1, padding=1), # B 256 8 8
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, stride=2, padding=0), # B 256 4 4
nn.Dropout2d(0.2, inplace=True),
nn.BatchNorm2d(num_features=256),
nn.Conv2d(256, 512, 3, stride=1, padding=1), # B 512 4 4
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 512, 3, stride=1, padding=1), # B 512 4 4
nn.LeakyReLU(0.2, inplace=True),
nn.MaxPool2d(2, stride=2, padding=0), # B 512 2 2
nn.Dropout2d(0.2, inplace=True)
)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential( # B 1 28 28
nn.BatchNorm2d(num_features=1),
nn.Conv2d(1, 64, 3, stride=1, padding=3), # B 64 32 32
nn.LeakyReLU(0.2),
nn.Conv2d(64, 64, 3, stride=1, padding=1), # B 64 32 32
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, stride=2, padding=0), # B 64 16 16
nn.Dropout2d(0.2, inplace=True),
nn.BatchNorm2d(num_features=64),
nn.Conv2d(64, 128, 3, stride=1, padding=1), # B 128 16 16
nn.LeakyReLU(0.2),
nn.Conv2d(128, 128, 3, stride=1, padding=1), # B 128 16 16
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, stride=2, padding=0), # B 128 8 8
nn.Dropout2d(0.2, inplace=True),
nn.BatchNorm2d(num_features=128),
nn.Conv2d(128, 256, 3, stride=1, padding=1), # B 256 8 8
nn.LeakyReLU(0.2),
nn.Conv2d(256, 256, 3, stride=1, padding=1), # B 256 8 8
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, stride=2, padding=0), # B 256 4 4
nn.Dropout2d(0.2, inplace=True),
nn.BatchNorm2d(num_features=256),
nn.Conv2d(256, 512, 3, stride=1, padding=1), # B 512 4 4
nn.LeakyReLU(0.2),
nn.Conv2d(512, 512, 3, stride=1, padding=1), # B 512 4 4
nn.LeakyReLU(0.2),
nn.MaxPool2d(2, stride=2, padding=0), # B 512 2 2
nn.Dropout2d(0.2, inplace=True)
)
self.fc = nn.Sequential(
nn.Linear(2048, 512), # B 512
nn.LeakyReLU(0.2),
nn.Dropout(0.5, inplace=True),
nn.Linear(512, 256), # B 256
nn.LeakyReLU(0.2),
nn.Dropout(0.5, inplace=True),
nn.Linear(256, 1), # B 1
nn.Sigmoid()
)
def forward(self, full_image):
# full_image B 28 28
full_image = full_image.unsqueeze(1) # B 1 28 28
out = self.conv(full_image) # B 512 2 2
out = out.flatten(1) # B 2048
out = self.fc(out) # B 1
out = out.squeeze() # B
return out
class Generator(nn.Module):
def __init__(self, conv:nn.Module):
super().__init__()
self.conv = conv
self.noise_fc = nn.Sequential( # B 100
nn.Linear(100, 1024), # B 1024
nn.LeakyReLU(0.2, inplace=True)
)
self.dc = nn.Sequential( # B 1024 2 1
nn.BatchNorm2d(1024),
nn.ConvTranspose2d(1024, 512, 4, stride=2, padding=1, bias=False), # B 512 4 2
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(512, 512, 3, stride=1, padding=1), # B 512 4 2
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(512),
nn.ConvTranspose2d(512, 256, 4, stride=2, padding=1, bias=False), # B 256 8 4
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 256, 3, stride=1, padding=1), # B 256 8 4
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(256),
nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1, bias=False), # B 128 16 8
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 128, 3, stride=1, padding=1), # B 128 16 8
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1, bias=False), # B 64 32 16
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64, 3, stride=1, padding=0), # B 64 30 14
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(64),
nn.Conv2d(64, 64, 3, stride=1, padding=(0, 1)), # B 64 28 14
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64, 3, stride=1, padding=1), # B 64 28 14
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 1, 3, stride=1, padding=1), # B 1 28 14
nn.ReLU(inplace=True),
)
def forward(self, z, left):
# z B 100
# left B 28 14
left = left.unsqueeze(1) # B 1 28 14
with torch.no_grad():
condition_features = self.conv(left) # B 512 2 1
condition_features = condition_features.flatten(1).unsqueeze(2) # B 1024 1
noise_features = self.noise_fc(z).unsqueeze(2) # B 1024 1
dc_input = torch.cat((condition_features, noise_features), dim=2).unsqueeze(3) # B 1024 2 1
constructed = self.dc(dc_input) # B 1 28 14
constructed = constructed.squeeze(1) # B 28 14
return constructed.clamp(0, 1)
Train your GAN¶
Write the training process below. Feel free to add extra cells.
Pretrained Convolutional encoder with an Autoencoder¶
First, we train an autoencoder to use its trained encoder in generator and discriminator encoders.
def get_batches(X, y=None, batch_size=128, shuffle=True):
if y is not None:
assert X.shape[0] == y.shape[0]
num_batches = int(np.ceil(X.shape[0] * 1.0 / batch_size))
if shuffle:
indices = np.random.permutation(X.shape[0])
X = X[indices]
if y is not None:
y = y[indices]
for batch in range(num_batches):
start = batch * batch_size
end = min((batch + 1) * batch_size, X.shape[0])
yield (batch, X[start:end], y[start:end]) if y is not None else (batch, X[start:end])
def draw(images, texts, columns=1, rows=1):
fig = plt.figure(figsize=(2 * columns, 2 * rows))
for i in range(columns * rows):
ax = fig.add_subplot(rows, columns, i + 1)
ax.set_title(texts[i])
ax.set_aspect('equal')
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.imshow(images[i].reshape((28, 28)))
cax = fig.add_axes([0.12, 0.1, 0.78, 0.8])
cax.get_xaxis().set_visible(False)
cax.get_yaxis().set_visible(False)
cax.set_frame_on(False)
plt.show()
class Autoencoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = ImageConv()
self.decoder = nn.Sequential( # B 512 2 2
nn.BatchNorm2d(512),
nn.ConvTranspose2d(512, 256, 4, stride=2, padding=1, bias=False), # B 256 4 4
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 256, 3, stride=1, padding=1), # B 256 4 4
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(256),
nn.ConvTranspose2d(256, 128, 4, stride=2, padding=1, bias=False), # B 128 8 8
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 128, 3, stride=1, padding=1), # B 128 8 8
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(128),
nn.ConvTranspose2d(128, 64, 4, stride=2, padding=1, bias=False), # B 64 16 16
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 64, 3, stride=1, padding=1), # B 64 16 16
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(64),
nn.ConvTranspose2d(64, 32, 4, stride=2, padding=1, bias=False), # B 64 32 32
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(32, 32, 3, stride=1, padding=0), # B 64 30 30
nn.LeakyReLU(0.2, inplace=True),
nn.BatchNorm2d(32),
nn.Conv2d(32, 1, 3, stride=1, padding=0), # B 1 28 28
nn.ReLU(inplace=True)
)
def forward(self, b_x):
# b_x B 28 28
b_x = b_x.unsqueeze(1) # B 1 28 28
encoded = self.encoder(b_x) # B 512 2 2
decoded = self.decoder(encoded) # B 1 28 28
decoded = decoded.squeeze(1)
return decoded
def train_autoencoder(model, optimizer, X, batch_size):
epoch_loss = 0
iter = 0
model.train()
for iter, b_X in get_batches(X, batch_size=batch_size):
images = torch.tensor(b_X, device='cuda')
prediction = model(images)
loss = F.mse_loss(prediction, images)
epoch_loss += float(loss)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if (iter + 1) % 50 == 0:
print(f'[Train] Iteration {iter + 1:3d} - loss: {epoch_loss / (iter + 1):.2e}')
epoch_loss /= (iter + 1)
return epoch_loss
def evaluate_autoencoder(model, X, batch_size, return_predictions=False):
epoch_loss = 0
iter = 0
predictions = []
with torch.no_grad():
model.eval()
for iter, b_X in get_batches(X, batch_size=batch_size, shuffle=False):
images = torch.tensor(b_X, device='cuda')
prediction = model(images)
predictions.append(prediction.cpu().numpy())
loss = F.mse_loss(prediction, images)
epoch_loss += float(loss)
if (iter + 1) % 50 == 0:
print(f'[Valid] Iteration {iter + 1:3d} - loss: {epoch_loss / (iter + 1):.2e}')
epoch_loss /= (iter + 1)
if return_predictions:
return np.concatenate(predictions, axis=0), epoch_loss
return epoch_loss
autoencoder = Autoencoder().cuda()
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=1e-4)
batch_size = 256
epochs = 200
train_loss = []
val_loss = []
best_val_loss = float('inf')
for e in range(epochs):
start_time = time()
epoch_train_loss = train_autoencoder(autoencoder, optimizer, images_train, batch_size)
epoch_val_loss = evaluate_autoencoder(autoencoder, images_val, batch_size)
end_time = time()
if epoch_val_loss < best_val_loss:
best_val_loss = epoch_val_loss
torch.save(autoencoder.encoder.state_dict(), 'drive/MyDrive/mnist-autoencoder-conv-model.pt')
print(f'Epoch {e+1:3} finished in {end_time - start_time:.2f}s - Train loss: {epoch_train_loss:.2e} - Val loss: {epoch_val_loss:.2e}')
train_loss.append(epoch_train_loss)
val_loss.append(epoch_val_loss)
fig = plt.figure(figsize=(7.5, 7))
# loss
ax = fig.add_subplot(111)
ax.set_title('Loss / Epoch')
ax.set_ylabel('Loss')
ax.set_xlabel('Epoch')
ax.set_aspect('auto')
plt.plot(train_loss, label='Train', color='green', linewidth=3)
plt.plot(val_loss, label='Validation', color='red', linewidth=3)
plt.ylim((0, 2e-2))
plt.legend()

predictions, test_loss = evaluate_autoencoder(autoencoder, images_test, batch_size=batch_size, return_predictions=True)
test_loss
rows = 8
columns = 10
indices = np.random.choice(np.arange(len(images_test)), size=rows * columns // 2)
images = np.zeros((rows * columns // 2, 2, 28, 28))
images[:,0] = images_test[indices].reshape(rows * columns // 2, 28, 28)
images[:,1] = predictions[indices].reshape(rows * columns // 2, 28, 28)
images = images.reshape(rows * columns, 28, 28) * 255
texts = np.zeros((rows * columns // 2, 2), dtype=object)
texts[:,0] = np.array(['real' for _ in range(rows * columns // 2)])
texts[:,1] = np.array(['reconstructed' for _ in range(rows * columns // 2)])
texts = texts.reshape(rows * columns)
draw(images, texts, columns, rows)

Train the Conditional DCGAN for constructing right half of an image given the left half of it¶
def generator_train_step(generator, discriminator, b_images, g_optimizer, criterion):
g_optimizer.zero_grad()
B = b_images.shape[0]
z = torch.randn(B, 100, device='cuda')
cuda_images = torch.tensor(b_images, device='cuda')
left = cuda_images[:, :, :14] # B 28 14
right = cuda_images[:, :, 14:] # B 28 14
fake_right = generator(z, left) # B 28 14
validity = discriminator(torch.cat((left, fake_right), dim=2)) # B
g_loss = criterion(validity, torch.ones(B, device='cuda'))
g_loss.backward()
g_optimizer.step()
return float(g_loss)
def discriminator_train_step(generator, discriminator, b_images, d_optimizer, criterion):
d_optimizer.zero_grad()
B = b_images.shape[0]
real_images = torch.tensor(b_images[:B//2], device='cuda') # B/2 28 28
fake_images = torch.tensor(b_images[B//2:], device='cuda') # B/2 28 28
z = torch.randn(fake_images.shape[0], 100, device='cuda')
left = fake_images[:, :, :14]
with torch.no_grad():
fake_right = generator(z, left).detach() # B/2 28 14
generated_images = torch.cat((left, fake_right), dim=2) # B/2 28 28
discriminator_inputs = torch.cat((real_images, generated_images), dim=0) # B 28 28
expected = torch.cat((torch.ones(real_images.shape[0], device='cuda'), torch.zeros(generated_images.shape[0], device='cuda')), dim=0) # B
validity = discriminator(discriminator_inputs) # B
d_loss = criterion(validity, expected)
d_loss.backward()
d_optimizer.step()
return float(d_loss)
def train_GAN(generator, discriminator, images, g_optimizer, d_optimizer, criterion, batch_size, discriminator_step):
epoch_g_loss = 0
g_count = 0
epoch_d_loss = 0
d_count = 0
generator.train()
discriminator.train()
for iter, b_images in get_batches(images, batch_size=batch_size):
if (iter + 1) % discriminator_step == 0:
d_loss = discriminator_train_step(generator, discriminator, b_images, d_optimizer, criterion)
d_count += 1
epoch_d_loss += d_loss
else:
g_loss = generator_train_step(generator, discriminator, b_images, g_optimizer, criterion)
g_count += 1
epoch_g_loss += g_loss
epoch_g_loss /= g_count * 1.0
epoch_d_loss /= d_count * 1.0
return epoch_g_loss, epoch_d_loss
def display_GAN(generator, images, columns, rows):
with torch.no_grad():
generator.eval()
for _, batch in get_batches(images, batch_size=columns * rows):
z = torch.randn(columns * rows, 100, device='cuda')
batch_images = torch.tensor(batch, device='cuda')
left = batch_images[:, :, :14]
right = generator(z, left)
generated_images = torch.cat((left, right), dim=2).cpu().numpy() * 255 # row*col 28 28
images_to_show = np.zeros((rows * columns, 2, 28, 28))
images_to_show[:,0] = batch
images_to_show[:,1] = generated_images
images_to_show = images_to_show.reshape(rows * columns * 2, 28, 28)
texts = np.zeros((rows * columns, 2), dtype=object)
texts[:,0] = np.array(['real' for _ in range(rows * columns)])
texts[:,1] = np.array(['generated' for _ in range(rows * columns)])
texts = texts.reshape(rows * columns * 2)
draw(images_to_show, texts, columns * 2, rows)
break
imageconv = ImageConv()
imageconv.load_state_dict(torch.load('drive/MyDrive/mnist-autoencoder-conv-model.pt'))
generator = Generator(imageconv).cuda()
discriminator = Discriminator().cuda()
discriminator.conv.load_state_dict(torch.load('drive/MyDrive/mnist-autoencoder-conv-model.pt'))
criterion = nn.BCELoss()
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=1e-4)
g_optimizer = torch.optim.Adam(generator.parameters(), lr=1e-4)
batch_size = 256
epochs = 20
display_step = 1
discriminator_step = 6
g_loss = []
d_loss = []
generator_best_loss = float('inf')
discriminator_best_loss = float('inf')
for e in range(epochs):
start_time = time()
epoch_g_loss, epoch_d_loss = train_GAN(generator, discriminator, images_train, g_optimizer, d_optimizer, criterion, batch_size, discriminator_step)
end_time = time()
torch.save(discriminator.state_dict(), f'drive/My Drive/gan-discriminator-model-e{e:02d}.pt')
torch.save(generator.state_dict(), f'drive/My Drive/gan-generator-model-e{e:02d}.pt')
print(f'Epoch {e+1:3} finished in {end_time - start_time:.2f}s - Generator loss: {epoch_g_loss:.2e} - Discriminator loss: {epoch_d_loss:.2e}')
g_loss.append(epoch_g_loss)
d_loss.append(epoch_d_loss)
if e % display_step == 0:
display_GAN(generator, images_val, 5, 3)




















Plot Generator/Discriminator losses¶
fig = plt.figure(figsize=(7.5, 7))
# loss
ax = fig.add_subplot(111)
ax.set_title('Loss / Epoch')
ax.set_ylabel('Loss')
ax.set_xlabel('Epoch')
ax.set_aspect('auto')
plt.plot(g_loss, label='Generator', color='green', linewidth=3)
plt.plot(d_loss, label='Discriminator', color='red', linewidth=3)
plt.legend()

Draw examples¶
Draw real vs. generated images below (from the best epoch).
generator.load_state_dict(torch.load('drive/MyDrive/gan-generator-model-e09.pt'))
display_GAN(generator, images_test, 5, 20)

